


A groundbreaking solution that is transforming emergency preparedness for local government officials and organizations across the United States.

HeavyEco: The Weather Event Data Tool You Need to Know About – Register for the Webinar!

Business dynamics can change in seconds in today’s highly competitive global marketplace, and data is often the beating heart of that change. See how HEAVY.AI can give you "speed of thought" insights, regardless of the size and disparate nature of data sets.

Learn how HEAVY.AI scales with today's data driven economies.

Check out HEAVY.AI at the USGIF GEOINT Symposium on May 22, 2023!
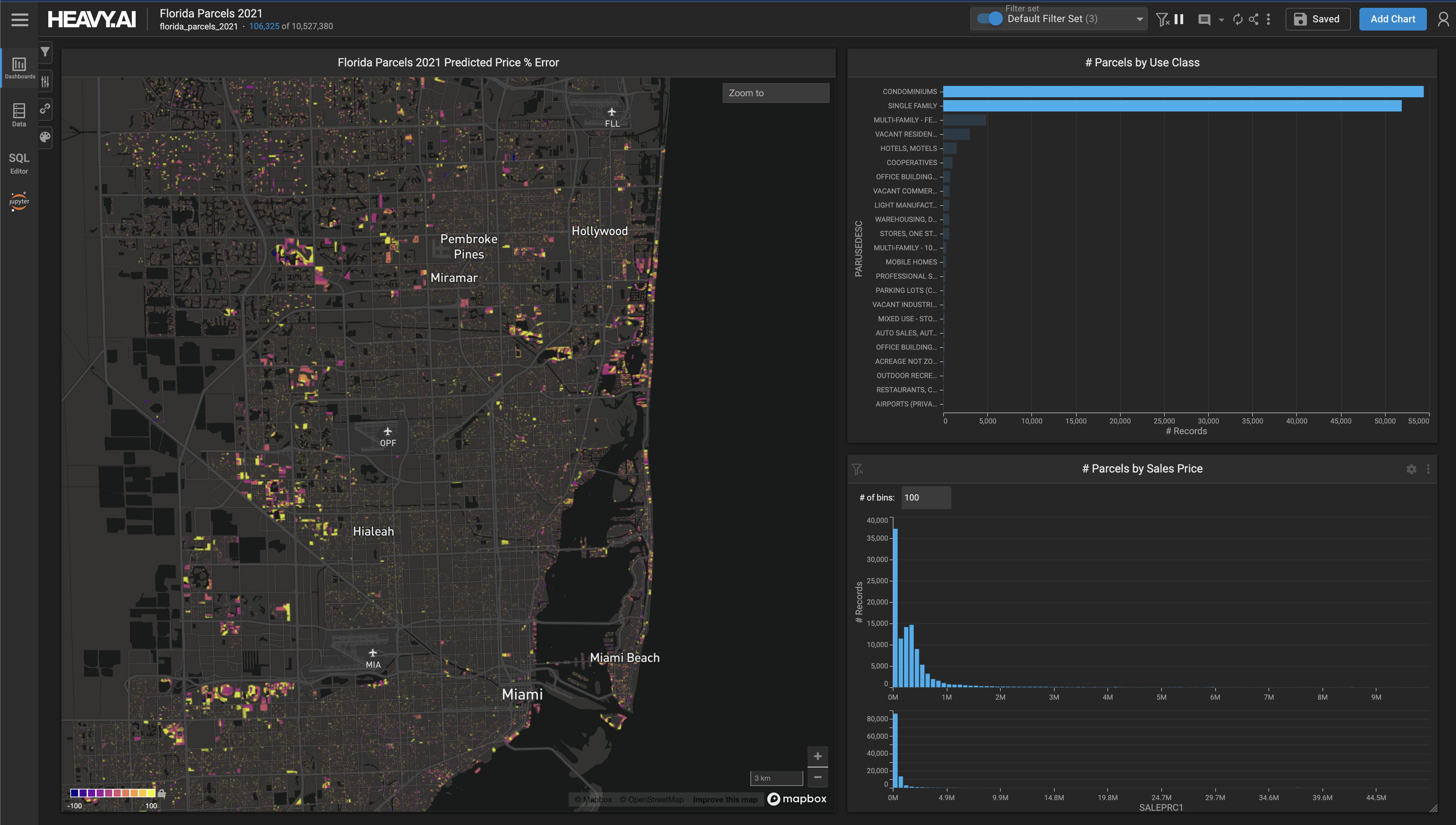
HeavyML allow users to orchestrate advanced data science and predictive analytics workflows directly using our accelerated HeavyDB SQL engine and Heavy Immerse interactive visual analytics frontend.

Component systems are a proven approach to managing user-interface complexity by allowing developers to break down complex interfaces into smaller, independent, reusable components

Learn how geospatial big data can help close the digital equity divide and accelerate enabling digital equity.
