

Announcing OmniSci Free
Try HeavyIQ Conversational Analytics on 400 million tweets
Download HEAVY.AI Free, a full-featured version available for use at no cost.
GET FREE LICENSENOTE: OMNISCI IS NOW HEAVY.AI
Ever since OmniSci’s founding (as MapD) back in 2013, we set out to build a platform that allows anyone to leverage data to understand the world, at the speed and scale of their curiosity. Along the way, we open-sourced our core database engine, along with interfaces for Python, Java, Javascript, Julia, and R. Then, with help from our partners at Quansight, Nvidia and Intel, we built deep integrations with the open data science ecosystem, including key components of the modern data science stack: Jupyter, Apache Arrow, Ibis, Altair, Modin and Nvidia Rapids. We’ve seen our customers and community users using these components to build amazing data-driven applications that showcase our mantra of bringing together interactivity and scale for data analytics in a way that was not possible before.
Over the last two years, however, it has become increasingly clear to us that our platform delivers the greatest value when leveraged in its full stack form, constituting an integrated user experience for visual analytics and data exploration. While OmniSciDB and the above open source components offer powerful capabilities for developers and data scientists, when coupled with OmniSci's Interactive Visual Analytics Platform, users suddenly gain the ability to go from question to insight with unparalleled speed on previously intractable datasets. And for large spatiotemporal datasets which are rapidly becoming the norm these days, our rendering engine provides the unprecedented capability to visualize and interact with billions of records on a map in full granularity.
However, since OmniSci Render and Immerse are not Apache-2.0 licensed like OmniSciDB, the power of our full stack has been largely inaccessible to our open source community of users. For a company with a mission to make “analytics instant, powerful, and effortless for everyone”, we’ve always longed for a frictionless way to offer the world the entirety of the OmniSci platform.
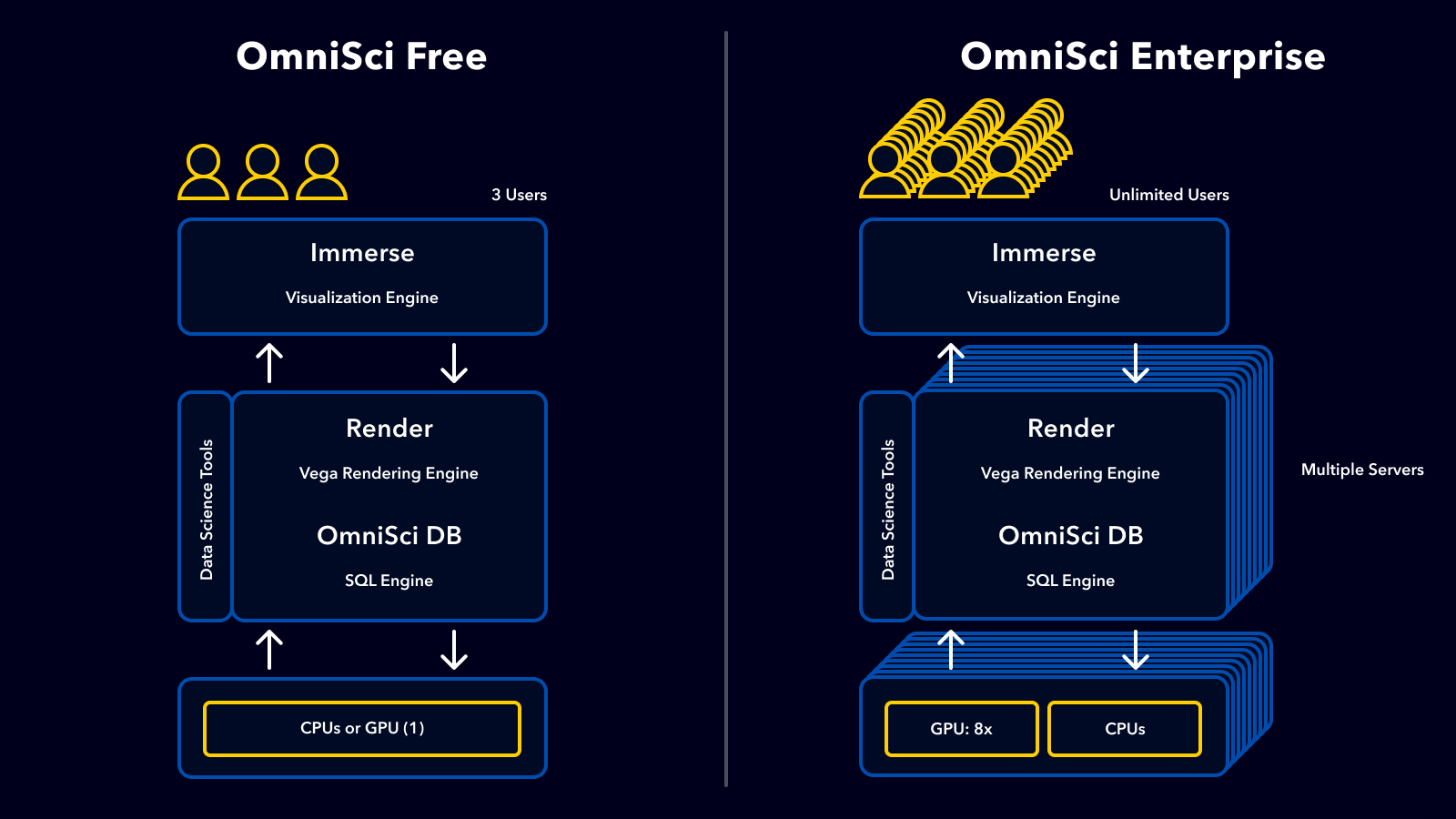
So today we’re thrilled to announce the launch of a free tier of our enterprise analytics product, aptly named OmniSci Free, for use on Linux-based platforms. To be clear, OmniSci Free is the complete OmniSci experience including the very latest in OmniSciDB, Render, Immerse and now our data science tools. You can use the OmniSci stack however you see fit, with up to 32GB memory capacity, which allows for interactive analysis of datasets of hundreds of millions of records, and 3 active user sessions. You can create as many users, dashboards, tables as you want within these limits. In addition, OmniSci Free can be installed with the OmniSci Data Science toolkit, which provides a full set of Python-based tools that are deeply integrated with OmniSci and accessible directly from Immerse.
To get started right away, register and download the OmniSci Free install package for your Linux-based server. To make it even easier to get started, OmniSci Free will be available on AWS marketplace shortly after launch, with support for Azure and Google Cloud marketplaces on our roadmap. Support for the native Linux package managers, apt and yum, are coming soon.
We welcome you to ask questions and learn more on the OmniSci community forums. When you’re ready to go bigger, you can sign up for the OmniSci hourly edition on AWS, or contact us to try our complete enterprise offering with full support and additional features.
We hope OmniSci Free provides a powerful tool for data analysts, data scientists, researchers, and ultimately anyone who is curious and believes in the power of data to answer their biggest questions. We look forward to seeing it drive use cases that are both familiar to us, and also those we cannot even begin to imagine.
Please let us know your thoughts, comments, or questions in our community forum, we’d love to hear from you.



