

Massive Is Now Mobile: OmniSci Comes to Life on Your Mac
Try HeavyIQ Conversational Analytics on 400 million tweets
Download HEAVY.AI Free, a full-featured version available for use at no cost.
GET FREE LICENSEOmniSci is now available to try on your Mac! To those who follow us, this might come as a surprise. Macs run on Intel CPUs (for now!), yet we’ve always been known as the pioneer of GPU-accelerated analytics. For years we’ve developed cutting edge database and visual analytics software that leverages the full might of top-shelf Nvidia graphics cards. But here’s the rub: not everyone has access to these Nvidia GPUs.
We decided to run a radical experiment: what if we could provide users with the ability to run OmniSci not only on big iron GPU-servers, but also leverage the power of the platform, with the same APIs and visual analytics interface, on the laptops and desktops they already have available?
Spoiler Alert: at a billion rows our Mac CPU experiment goes toe-to-toe with several famous big data analytics platforms. Until October 31st, we invite you to try it yourself, for free.
A few years ago Mark Litwinschik, the prolific technical blogger famous for his 1.1 billion row taxi benchmark, independently benchmarked OmniSci (then MapD) on a variety of GPU configurations on this dataset. We continue to be at or close to the top of those lists, despite having not updated our benchmarks or software versions on more modern hardware in over two years.
Earlier this year, we decided it was time to refresh these benchmarks, so we reached out to Mark with a proposal to rerun them. We will always obsess about our GPU performance and are working on ways to update the benchmarks to take advantage of Nvidia's insanely awesome Ampere GPUs. But this time around we looked at our mission statement, “Make analytics instant, powerful, and effortless for everyone,” and so we asked a new question. “What kind of hardware is accessible to everyone?”
This question drove us to identify a laptop used by data scientists and developers alike: The Macbook Pro. In this case, it’s the 16inch MacBook Pro with an 8-core Intel 9th Gen CPU and 64GB of RAM. Admittedly, this isn’t a run-of-the-mill machine, but it does represent the kind of power that is now accessible to a far larger audience. We set up Mark with this machine and the ability to independently run his benchmarks. A few weeks later, we got the results.
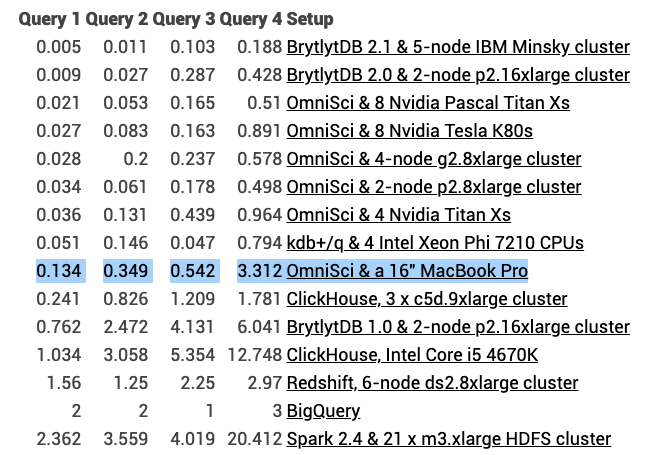
Suffice to say, the results surprised both Mark and us. We expected that we'd be able to run the four standard queries in his benchmark test quickly, and possibly be competitive with the luminaries in the 'Big SQL' arena, including Google Big Query, Clickhouse, and Spark. What we did not anticipate was soundly beating many of them, while running on a laptop.
Naturally our next step was to throw caution to the winds and develop an experimental build of our software, including our Immerse UI, natively for the Mac. Of course this experimental build isn’t comparable to our full enterprise offering (due to technical limitations of the Macs), but then again you don’t have a $12,000 GPU in your laptop bag.

What we’ve learned from our experiment is that not only can we handle the taxi dataset and the benchmark queries, but we think the experience of using Immerse on a Mac for massive data sets is unlike any other tool you may be familiar with. Other than the geospatial charts that currently depend on having a discrete GPU (our pointmap, line map, geo heatmap, and choropleth), all of the rest of Immerse works just fine. All powered by the same OmniSciDB engine that can scale to 100s of billions of rows of data. All working with the speed and fluidity you expect from OmniSci.
What does this mean? For starters, the benchmark itself reinforces our mindset that we can transform analytics by obsessively focusing on extracting all available performance from any hardware. The bigger point though, is about making this performance usable in a real way, by as many people as possible. It’s the reason why we thought about releasing this experiment to the world at large - and went ahead!
That's right! You can now download this Mac build and try it out yourselves for a three month period. This includes OmniSciDB and OmniSci Immerse (but no GPU-enabled render, ergo no geospatial charts - but we’re working on this). We hope you can see how transformative it is to have both interactivity and scale at your fingertips- no need to choose!
We stress that this is NOT a finished product (and not even a product, really an experiment), and is going to have a lot of rough edges around the peculiarities of running on a consumer grade machine. However, we do have plans on our Immerse and OmniSciDB roadmaps to add several necessary user-facing features to get us to a product and also fix any and all issues along the way. In the spirit of data curiosity and exploration, and certainly our mission statement, we're making this experimental build available to everyone.
If you’re on Windows, sorry for now. But stay tuned. :)
Over the next few weeks we'll show you how to do some neat things with big data sets on a laptop, including integration with data science tools! Finally, and just to repeat, this is not a finished, polished product. We’re sharing our experiment with you and we'd love to hear your feedback, on our community forum page. Testing the waters, if you will.
For Mark’s own take on this experiment, head on over to his blog - highly encouraged reading!



