
Demo Overview

In our final part of this three-part blog series, we explore how we created the charts, maps, and dashboards in Heavy Immerse.
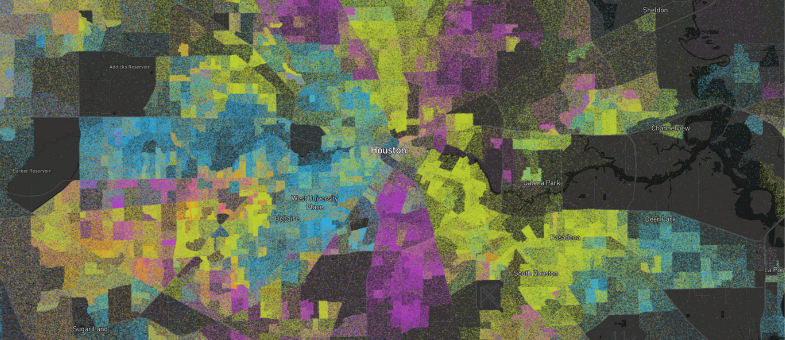
Last week we released our newest public demonstration that takes demographic dot density maps one step further by mapping data from the 1990, 2000, 2010, and 2020 censuses. In this post we discuss how we acquired the data for each census and the Python notebooks used to turn the census block group polygons into individual points.

In this post we took demographic dot density maps one step further by creating a set of Dot Density Dashboards that view over a billion census data points in real-time.

The following tutorial will use HEAVY.AI's JupyterLab integration and Immerse to ingest, analyze, and visualize GHCN data.

Earlier this month, our team shared 4 Simple Ways to Map Vehicle Location Data with OmniSci Free. We're following up to show you how we accessed and loaded OpenStreetMap (OSM) data in OmniSci Free, synthesized those streets with vehicle collisions, and delivered meaningful spatial insights.

Humans have always wanted to know what will happen next. In this post, we’ll explore how you can use the open-source forecasting procedure Facebook Prophet, OmniSci, and a historic time-series dataset to give a view into the future.



In this post, we use OmniSci to visualize a massive GPS mobility dataset, correlate our observations with historical censuses, and then predict census undercount.

People on the frontlines of the next phase of the COVID-19 response need interactive, large-scale data analysis. Read our most recent blog post on geospatial analysis of anonymized, geographic datasets to see how we are supporting national relief efforts.



