
Big Data Architecture
Big Data Architecture Definition
Big data architecture refers to the logical and physical structure that dictates how high volumes of data are ingested, processed, stored, managed, and accessed.
FAQs
What is Big Data Architecture?
Big data architecture is the foundation for big data analytics. It is the overarching system used to manage large amounts of data so that it can be analyzed for business purposes, steer data analytics, and provide an environment in which big data analytics tools can extract vital business information from otherwise ambiguous data. The big data architecture framework serves as a reference blueprint for big data infrastructures and solutions, logically defining how big data solutions will work, the components that will be used, how information will flow, and security details.
The architecture components of big data analytics typically consists of four logical layers and performs four major processes:
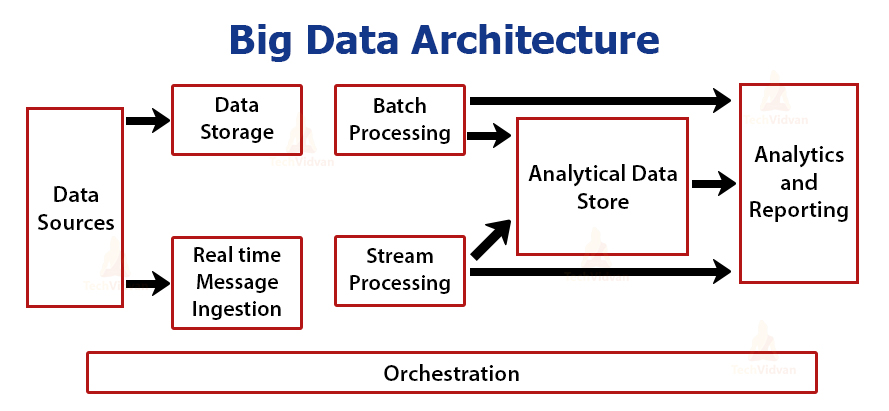
Big Data Architecture Layers
- Big Data Sources Layer: a big data environment can manage both batch processing and real-time processing of big data sources, such as data warehouses, relational database management systems, SaaS applications, and IoT devices.
- Management & Storage Layer: receives data from the source, converts the data into a format comprehensible for the data analytics tool, and stores the data according to its format.
- Analysis Layer: analytics tools extract business intelligence from the big data storage layer.
- Consumption Layer: receives results from the big data analysis layer and presents them to the pertinent output layer - also known as the business intelligence layer.
Big Data Architecture Processes
- Connecting to Data Sources: connectors and adapters are capable of efficiently connecting any format of data and can connect to a variety of different storage systems, protocols, and networks.
- Data Governance: includes provisions for privacy and security, operating from the moment of ingestion through processing, analysis, storage, and deletion.
- Systems Management: highly scalable, large-scale distributed clusters are typically the foundation for modern big data architectures, which must be monitored continually via central management consoles.
- Protecting Quality of Service: the Quality of Service framework supports the defining of data quality, compliance policies, and ingestion frequency and sizes.
In order to benefit from the potential of big data, it is crucial to invest in a big data infrastructure that is capable of handling huge quantities of data. These benefits include: improving understanding and analysis of big data, making better decisions faster, reducing costs, predicting future needs and trends, encouraging common standards and providing a common language, and providing consistent methods for implementing technology that solves comparable problems.
Big data infrastructure challenges include the management of data quality, which requires extensive analysis; scaling, which can be costly and affect performance if not sufficient; and security, which increases in complexity with big data sets.
Big Data Architecture Best Practices
Establishing big data architecture components before embarking upon a big data project is a crucial step in understanding how the data will be used and how it will bring value to the business. Implementing the following big data architecture principles for your big data architecture strategy will help in developing a service-oriented approach that ensures the data addresses a variety of business needs.
- Preliminary Step: A big data project should be in line with the business vision and have a good understanding of the organizational context, the key drivers of the organization, data architecture work requirements, architecture principles and framework to be used, and the maturity of the enterprise architecture. It is also important to have a thorough understanding of the elements of the current business technology landscape, such as business strategies and organizational models, business principles and goals, current frameworks in use, governance and legal frameworks, IT strategy, and any pre-existing architecture frameworks and repositories.
- Data Sources: Before any big data solution architecture is coded, data sources should be identified and categorized so that big data architects can effectively normalize the data to a common format. Data sources can be categorized as either structured data, which is typically formatted using predefined database techniques, or unstructured data, which does not follow a consistent format, such as emails, images, and Internet data.
- Big Data ETL: Data should be consolidated into a single Master Data Management system for querying on demand, either via batch processing or stream processing. For processing, Hadoop has been a popular batch processing framework. For querying, the Master Data Management system can be stored in a data repository such as NoSQL-based or relational DBMS
- Data Services API: When choosing a database solution, consider whether or not there is a standard query language, how to connect to the database, the ability of the database to scale as data grows, and which security mechanisms are in place.
- User Interface Service: a big data application architecture should have an intuitive design that is customizable, available through current dashboards in use, and accessible in the cloud. Standards like Web Services for Remote Portlets (WSRP) facilitate the serving of User Interfaces through Web Service calls.
How to Build a Big Data Architecture
Designing a big data reference architecture, while complex, follows the same general procedure:
- Analyze the Problem: First determine if the business does in fact have a big data problem, taking into consideration criteria such as data variety, velocity, and challenges with the current system. Common use cases include data archival, process offload, data lake implementation, unstructured data processing, and data warehouse modernization.
- Select a Vendor: Hadoop is one of the most widely recognized big data architecture tools for managing big data end to end architecture. Popular vendors for Hadoop distribution include Amazon Web Services, BigInsights, Cloudera, Hortonworks, Mapr, and Microsoft.
- Deployment Strategy: Deployment can be either on-premises, which tends to be more secure; cloud-based, which is cost effective and provides flexibility regarding scalability; or a mix deployment strategy.
- Capacity Planning: When planning hardware and infrastructure sizing, consider daily data ingestion volume, data volume for one-time historical load, the data retention period, multi-data center deployment, and the time period for which the cluster is sized
- Infrastructure Sizing: This is based on capacity planning and determines the number of clusters/environment required and the type of hardware required. Consider the type of disk and number of disks per machine, the types of processing memory and memory size, number of CPUs and cores, and the data retained and stored in each environment.
- Plan a Disaster Recovery: In developing a backup and disaster recovery plan, consider the criticality of data stored, the Recovery Point Objective and Recovery Time Objective requirements, backup interval, multi datacenter deployment, and whether Active-Active or Active-Passive disaster recovery is most appropriate.
Does HEAVY.AI Offer a Big Data Architecture Solution?
In the era of growing Artificial Intelligence, machine learning, and big data, many big data analytics users are adopting the concept of a data lake architecture, holding vast amounts of raw data in its native format until it is needed. It is imperative to incorporate the computing power of GPUs for processing and extracting insights from these enormous datasets with accuracy and at real-time speeds. As the pioneer in GPU-accelerated analytics, the HEAVY.AI platform is used to find insights in data beyond the limits of mainstream CPU-based analytics tools.