
Technical Deep-Dive
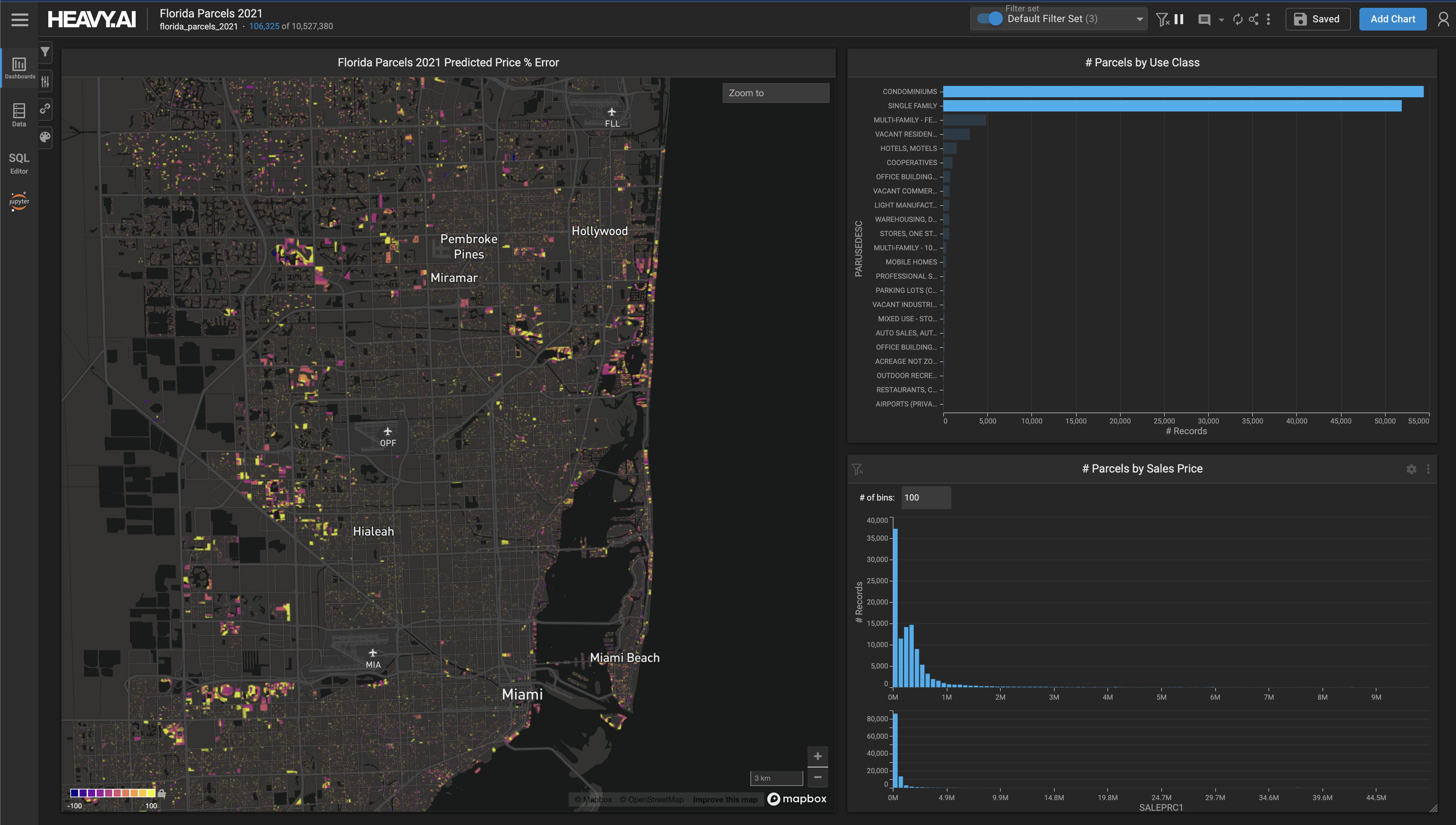
HeavyML allow users to orchestrate advanced data science and predictive analytics workflows directly using our accelerated HeavyDB SQL engine and Heavy Immerse interactive visual analytics frontend.

Component systems are a proven approach to managing user-interface complexity by allowing developers to break down complex interfaces into smaller, independent, reusable components

Bureaucracy in visual BI solutions is inefficient and downright uninspiring. Learn how decision makers interacting directly with data can empower insightful analysis.

This post will give an overview of our visual analytics dashboard parameters, show you how to set them up, and provide an example of how parameters promote a user-centric workflow.
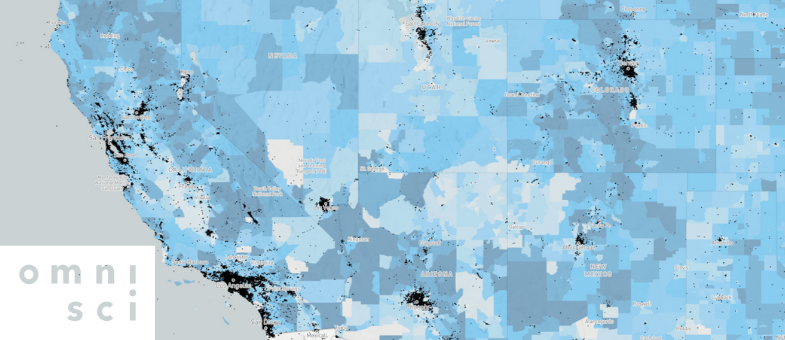
New spatial overlaps join framework provides 1000X+ speedups for point-in-polygon joins

This post examines flood risk data listed on the Registry of Open Data on AWS and demonstrates how to use OmniSci's native AWS S3 ingestion paths to load data into OmniSci.

Learn the benefits of using OmniSci to ingest real-time satellite location data and how we can utilize the loading, visualization, and querying aspects of the product to find insights.

In this article, we'll demonstrate the ease of using Jupyter notebooks with open source Python libraries for visual charts to interact with data in OmniSci Database on a Mac.





