

Announcing OmniSci 4.6
Try HeavyIQ Conversational Analytics on 400 million tweets
Download HEAVY.AI Free, a full-featured version available for use at no cost.
GET FREE LICENSEThe first few months of 2019 have been productive and exciting here at OmniSci. We were featured prominently at two separate conferences in March, which kept us all busy! GTC in San Jose had a great start with NVIDIA CEO Jensen Huang’s highly anticipated keynote. As always, it was full of amazing product announcements and demos, and we were honored to be a highlight of Jensen’s keynote for NVIDIA’s rapidly (no pun intended) developing push into data science. Working with data from a large mobile network operator, we partnered with Datalogue to build an end-to-end demo of data science leveraging NVIDIA’s Rapids toolkit and a Data Science Workstation from BOXX.
Here’s Jensen and OmniSci VP of Global Community, Aaron Williams, demonstrating OmniSci’s real-time GPU analytics capabilities visualized in our oft-rumored but elusive “dark mode.”

At the Gartner Data and Analytics Summit in Orlando, we partnered with Cambridge Mobile Telematics to showcase the power of interactive, visual, GPU-accelerated analytics in exploring and understanding driver behavior across half a billion observations. You can read more details about both these demos here.

In the midst of all of this, our amazing engineering team has been hard at work, delivering OmniSci 4.6 this week. Since OmniSci 4.0 last June, this release represents the largest collection of new features and improvements delivered to date across our platform. We’re happy to share the release with our users and community and look forward to delivering more exciting features leading up to OmniSci 5.0.
OmniSci Core
We moved to rationalize our product offerings in the last 4.5 release, with the launch of OmniSci Enterprise Trial and OmniSci Open Source (pre-built, downloadable). In the months since, we completed work on several new features requested by our customers and community.
First, we continue to focus on performance and scalability as the differentiating bedrocks of our platform. CTAS(CREATE TABLE AS SELECT) is a common utility SQL capability that is used in the early stages of data exploration and analysis to shape the dataset from raw data, usually by applying functions to specific columns in the SQL SELECT clause. We made foundational improvements to CTAS to work on larger, distributed installations, removing a key limitation until now. Secondly, we made several improvements on String Dictionaries, lifting the limit on entries to 2 billion, improving performance by 25-35% on reloads from better thread utilization and improving lookup performance from the use of the Rabin-Karp algorithm for searching.
On the rendering side, we significantly improved the scalability of rendering larger result sets from projection (i.e. non aggregate) queries. With our 4.6 release, users can render the entirety of the US building footprint database (123 million polygons from the Open Street Map database, open sourced by Microsoft Azure) on a single machine. Here’s a zoomed in view of that dataset, showing 400k buildings in the New York City Area). We also raised the ceiling on sampling for geo charts from 2 million to 10 million, allowing for even greater levels of detail in these charts.

On the SQL side, we extended UPDATE to work on variable length columns, as well as allowing nullable variable length array columns. We also added support for high-precision timestamps, and now allow up to nanosecond precision (TIMESTAMP(9)). We are working to add this to Immerse in an upcoming release.
We are also happy to announce support for Single Sign On with SAML authentication (available only in OmniSci Enterprise edition) - this has been integrated into Immerse, as well. The product currently integrates with Okta, and we’re exploring other identity providers including OpenID Connect and OAuth based on customer interest.
On the import/data ingestion side, we added support for importing from Apache Parquet files, both local and from AWS S3 via our COPY FROM SQL command using omnisql, including support for the \detect utility to extract schema information into a CREATE TABLE DDL statement. We're now working on allowing Parquet as a native storage format, such that OmniSci can attach to existing Parquet data stores without duplicating the data.
Based on a longstanding request from our customers who use OmniSci in geospatial workflows, we now support importing from Esri geodatabase (.gdb) files.
In addition to all of the new capabilities above, we fixed several bugs in our continued efforts to make the OmniSci platform more stable, reliable, and performant. Please refer to our release notes for further details.
OmniSci Immerse
OmniSci 4.6 introduces greater flexibility within Data Manager. A longstanding request from customers was the ability to manage data tables directly from Data Manager, so we’ve added the following actions:

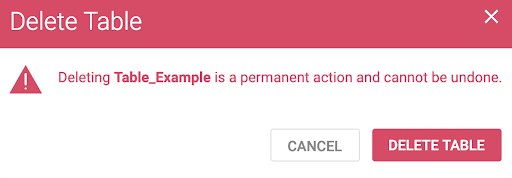
- Delete Table, giving users the ability to delete tables directly from Immerse (equivalent to SQL ‘DROP TABLE’)
- Delete All Rows, giving users the ability to delete all rows within a table, while keeping the table itself (equivalent to SQL ‘TRUNCATE TABLE’)
- Append Data, giving users the ability to append more data rows to an existing table
These actions are all subject to users having the appropriate SQL permissions to do so. Given the potential impact of taking these actions, we introduced new error messaging (see example below) for the Delete options, and data validation for Append Data to ensure that any new data appended fits the structure of the existing data table.
Within Data Import, we added the Includes Header Row option in Import Settings—this has been another long-standing request from customers. For tables containing all text columns, it can be challenging for auto-detection to differentiate data from a header row, and this also helps when appending data to existing tables.

For a longer list of features and fixes in the release, check out our release notes. For details on how to use them, please refer to the latest help docs. We look forward to hearing your feedback!
For new users, OmniSci 4.6 can be accessed through a variety of ways: download a pre-built version of our Open Source edition, sign up for our 30-day Enterprise Trial on our downloads page, or get instant access with a free 14-day trial by signing up for OmniSci cloud.



