

Announcing the Release of MapD 3.5
Try HeavyIQ Conversational Analytics on 400 million tweets
Download HEAVY.AI Free, a full-featured version available for use at no cost.
GET FREE LICENSEWe’re pleased to announce the public availability of MapD version 3.5.
While the primary work in this release focused on stability and bug fixes, we also have some key new features in both MapD Core and MapD Immerse that we are excited to make available to our users.
New MapD Core features in Release 3.5
Importing Files Directly from S3
A number of customers run MapD on cloud platforms, such as AWS and GCP, providing them a range of options for GPU-enabled instances. Now that list includes the recently launched P3 instances at AWS, featuring NVIDIA’s latest Volta-based GPU cards..
With version 3.5, customers can load data in S3 buckets using the COPY FROM command. Please refer to the updated docs for greater detail on the feature, but in a nutshell, the COPY FROM command now accepts additional parameters in the WITH clause, for the AWS credentials and bucket information, as follows:
COPY <table> FROM
<S3_file_URL>'
WITH (s3_access_key = <key_name>,
s3_secret_key = <key_name>,
s3_region = <region>);
For example,
mapdql> COPY trips FROM
's3://mapd-parquet-testdata/trip.compressed/'
WITH
<(s3_access_key=’xxxxxxxx’,s3_secret_key='yyyyyyyy',s3_region='us-west-1');
Result
Loaded: 105200 recs, Rejected: 0 recs in 1.890000 secs
A few points to note:
- The import can load multiple uncompressed and compressed files from a single bucket path into the target table. Note that all these files will be imported into the same target table specified in the COPY FROM.
- You need to have valid AWS access and secret keys and specify the bucket region.
- Currently only the command-line utility mapdql allows for import from S3. We’re working on a web UI in a future release that will integrate this capability, and also other administrative/operational features. Stay tuned!
Reading from Kafka Topics
As you’ve probably seen in many of our interactive demos, like Shipping Traffic and Mobile Network Quality, one of MapD’s strengths is providing interactive visual analytics over large geospatial and geotemporal datasets, such as timestamped events aggregated from large numbers of geographically dispersed sensors. Often, these sources produce data streams, so customers use event data platforms like Kafka to organize and distribute this information, including to downstream analytics platforms such as MapD.
We are excited to release KafkaImporter, a simple command line utility, enabling Kafka integration to be initiated and managed from within MapD..
KafkaImporter simply connects a Kafka topic to a MapD target table, and currently provides for the ability to import messages from a Kafka topic into that table.
As always, please refer to the updated documentation for details on the specific parameters. Here’s a simple usage example
/KafkaImporter tweets_small mapd
-u mapd
-p HyperInteractive
--delim '\t'
--batch 100000
--retry_count 360
--retry_wait 10
--null null
--port 9999
--brokers=localhost:9092
--group-id=testImport1
--topic=tweet
A few relevant usage notes and limitations:
- Both the MapD table and Kafka topic need to be pre-defined (the utility will not create these automatically)
- Currently, KafkaImporter maps a single message in a Kafka topic to a single row in the target MapD table.
- Only delimited row formats are currently supported. The --delim parameter allows a user to specify the delimiter.
- The KafkaImporter utility does not provide ordering guarantees or handle other tricky problems inherent in management of streaming data. For a great discussion of these, please see "Streaming 101" and "Streaming 102". You may want to investigate using one of several stream processing platforms to handle these issues, as part of designing a streaming load pipeline into MapD.
- KafkaImporter is the first step in improving our overall handling of streaming data to support operational analytics. Stay tuned for more product capabilities in this area.
StreamImporter
In addition to the KafkaImporter utility described above, release 3.5 of MapD also ships with a new utility called StreamImporter.
StreamImporter is an updated version of the StreamInsert utility that provided for streaming reads from delimited files into MapD core. The difference is that StreamImporter uses a binary columnar load path, providing improved performance compared to the StreamInsert utility.
Using StreamImporter is straightforward
./StreamImporter tweets_small mapd
-u mapd
-p HyperInteractive
--delim '\t'
--batch 100000
--retry_count 360
--retry_wait 10
--null null
--port 9999
Some usage notes:
- The StreamImporter utility also requires that the target table be created prior to load (it will not create the table automatically)
AutoComplete in Mapdql
Along with SQLEditor (see below), mapdql also now supports tab-based AutoComplete hints to allow for easier query construction. AutoComplete provides contextual hints, and helps you avoid typos in table names or sql keywords.

Performance Improvements - Rendering and MapD Core
Since releasing version 3.3, we’ve made a number of substantial performance improvements in our rendering engine related to handling large numbers of polygons (>1 million) uploaded via shapefiles. Below are some early, preview examples of what’s now possible, using the NYC Buildings dataset (>1 million polygons representing buildings in New York City). We’ll soon be rolling this out more broadly in MapD Immerse.
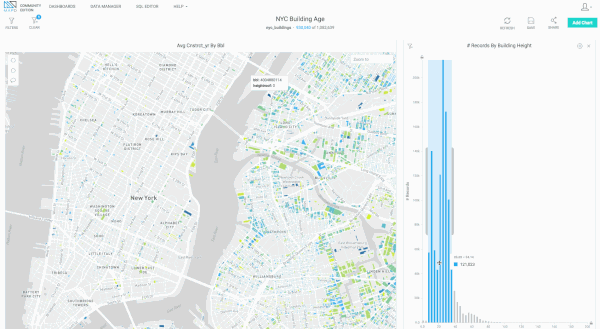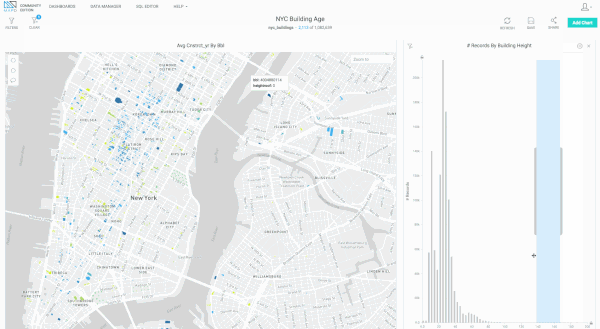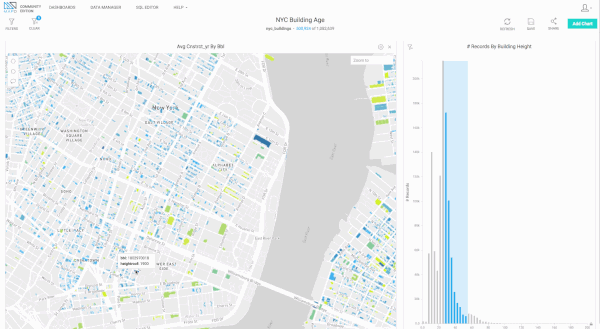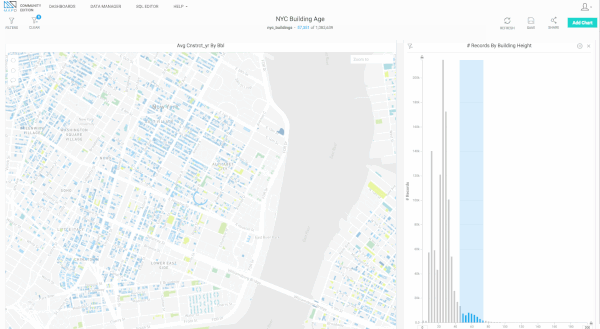
Bug Fixes
We’ve made several major and minor fixes across MapD core, covering product stability and customer-reported issues. Please see the release notes for details on these fixes.
New MapD Immerse Features in Release 3.5
SQL Editor Enhancements
In release 3.5 the SQLEditor in Immerse supports both syntax highlighting and auto-complete, allowing end users to easily construct queries.

Aggregations in Pointmap and Scatter plot
Both scatter plot and point map visualizations now support aggregations allowing users to group points by a dimension.

Support for the New Amazon P3 Instance type
With release 3.5, MapD now also supports the P3 instance types on AWS for both Community and Enterprise versions. These are the new GPU instances that feature the next-generation v100 GPU from NVIDIA, along with enhanced networking options.
Please refer to AWS pricing for the P3 AMI. Below is a summary table of the different P3 instance types for the MapD Community Edition.

You can also find the pricing for MapD Enterprise Edition on AWS here.
We’ll follow up with a blog post on the specific performance gains from moving to the next generation of NVIDIA Volta GPUs.
See the release notes for more details on these improvements, as well as information about bug fixes for this release. As always, please head on over to our downloads page, and let us know what you think on our community forums.



