

Traffic, Weather and Incidents: a 360 Degree View of California Commutes
Try HeavyIQ Conversational Analytics on 400 million tweets
Download HEAVY.AI Free, a full-featured version available for use at no cost.
GET FREE LICENSEIn my prior post, we examined traffic in the San Francisco Bay area from 2015-2019. Using OmniSci Enterprise Edition on a Microsoft Azure ND24s instance (4 GPU/96GB of GPU RAM), we could effortlessly analyze a billion rows of time series traffic data. One key takeaway is that traffic is cyclic and usually predictable. It doesn’t take many commutes to learn that traffic is horrendous in the morning hours as well as in the evening hours during the work week (shocking, I know!) But what about when traffic is extra bad? We’ve all sat through an unusual traffic congestion caused by some external forces, not just due to more cars on the road. What else negatively affects traffic?
After growing up through countless hurricanes and tropical storms in Florida and surviving through blistering cold winters in Pennsylvania, one very real contributor to traffic I’ve dealt with is the weather. However, in an area with 259 sunny days a year and an enviously Mediterranean-like climate, does the weather affect how Bay Area residents drive? Two hypotheses can be tested:
- The weather is mild enough that the Bay Area traffic is negligibly affected by weather conditions
- Californian drivers are inexperienced in driving through inclement weather, causing traffic to slow down
In order to test these hypotheses, let’s grab data from the National Climate Data Center (NCDC) for January to the end of February of 2019.
Examining the Microclimates of the Bay Area
The following features are of interest from the NCDC dataset:
- Hourly precipitation
- Hourly visibility
- Hourly temperature
- Hourly wind speed
Depending on the location, San Francisco Bay Area temperatures can range 10-30 degrees Fahrenheit each day. In the map below, you can see the 19 weather station locations throughout the Bay Area, which helps us visualize these microclimates in the region.


In the image above, we can see one day where the range in temperatures between stations was about 12 degrees in difference.
In the Bay Area, the peak rainy season is January and February. Let’s look at how the weather changes as we slide over the weeks:
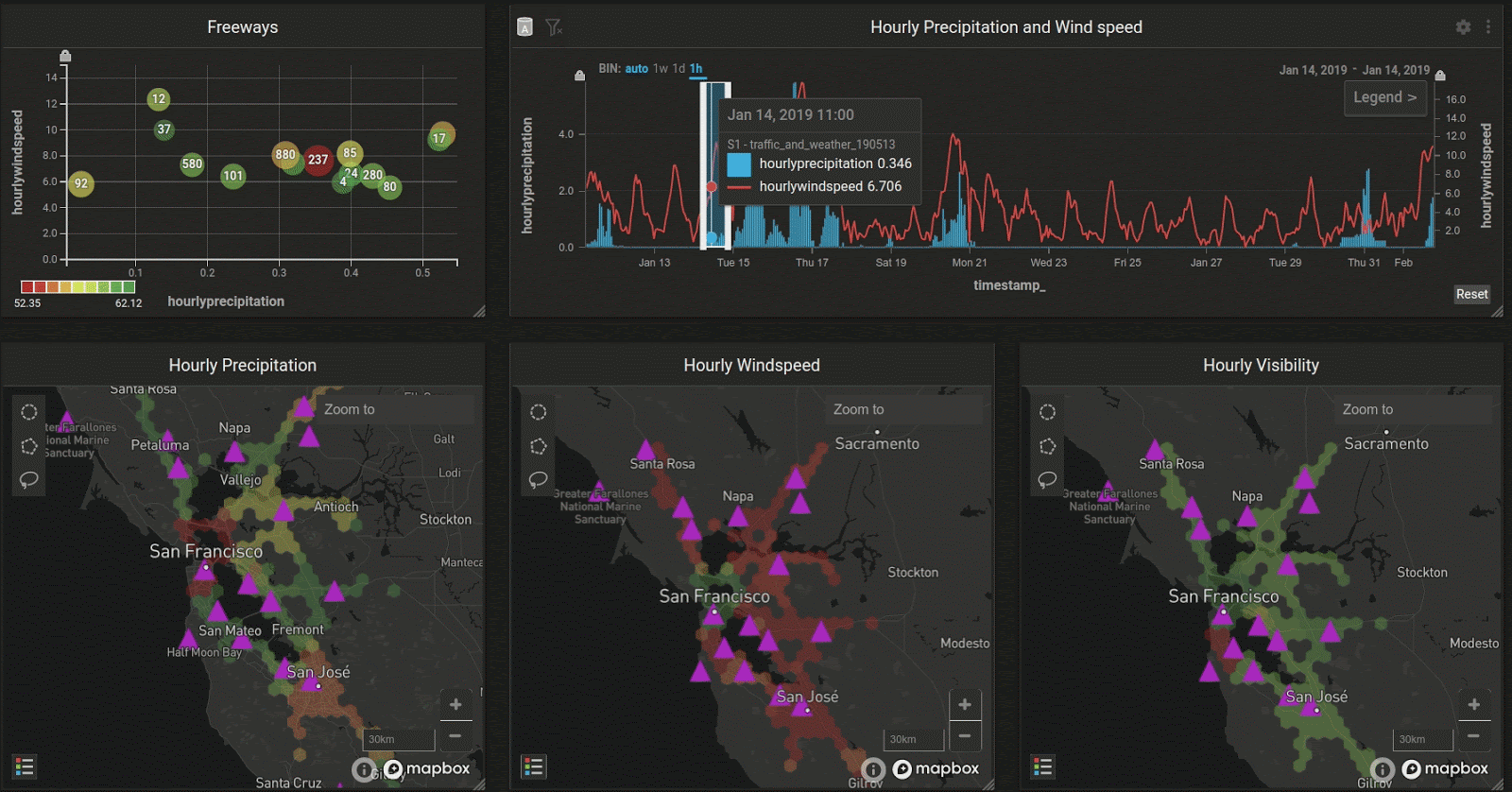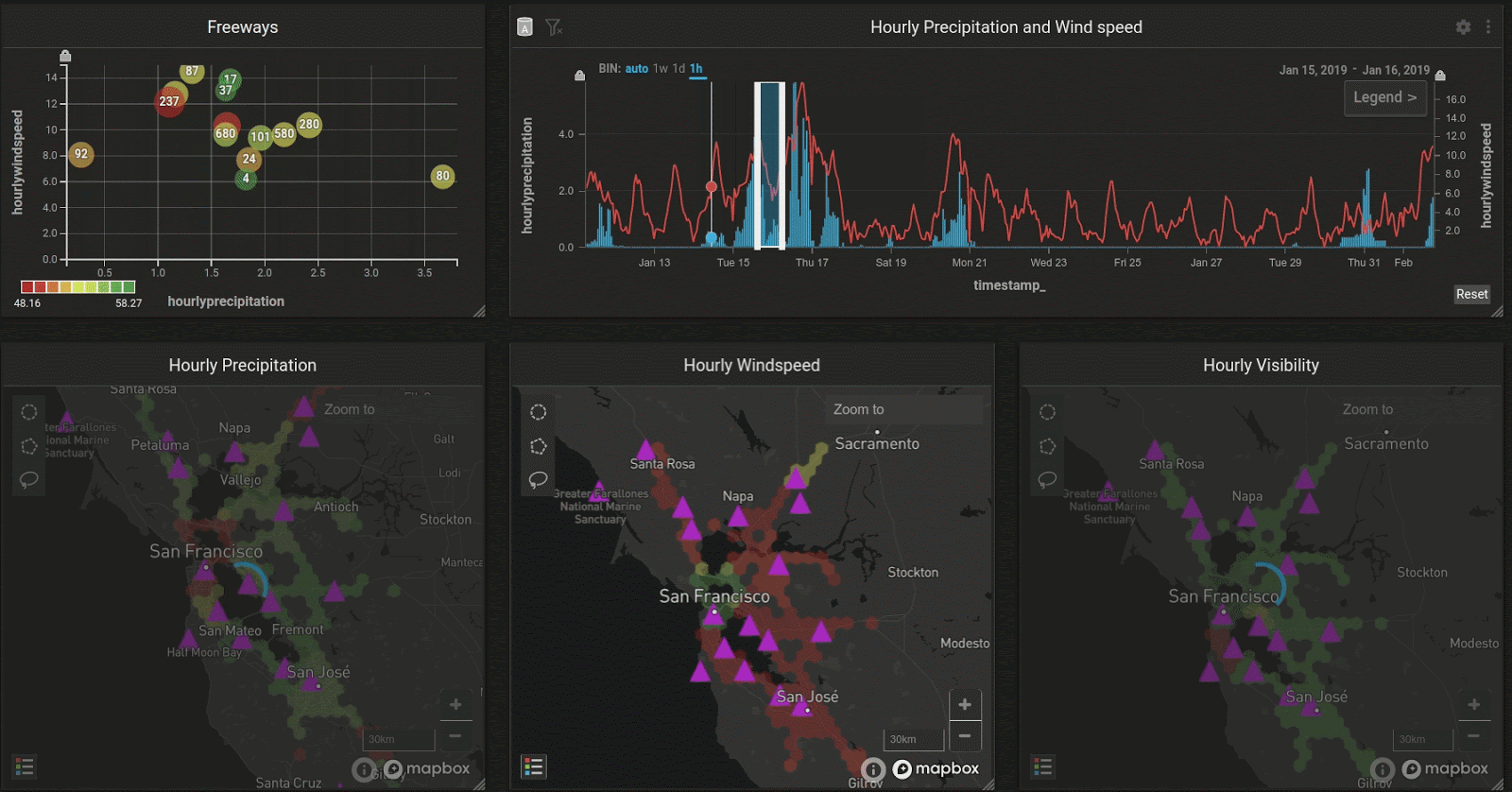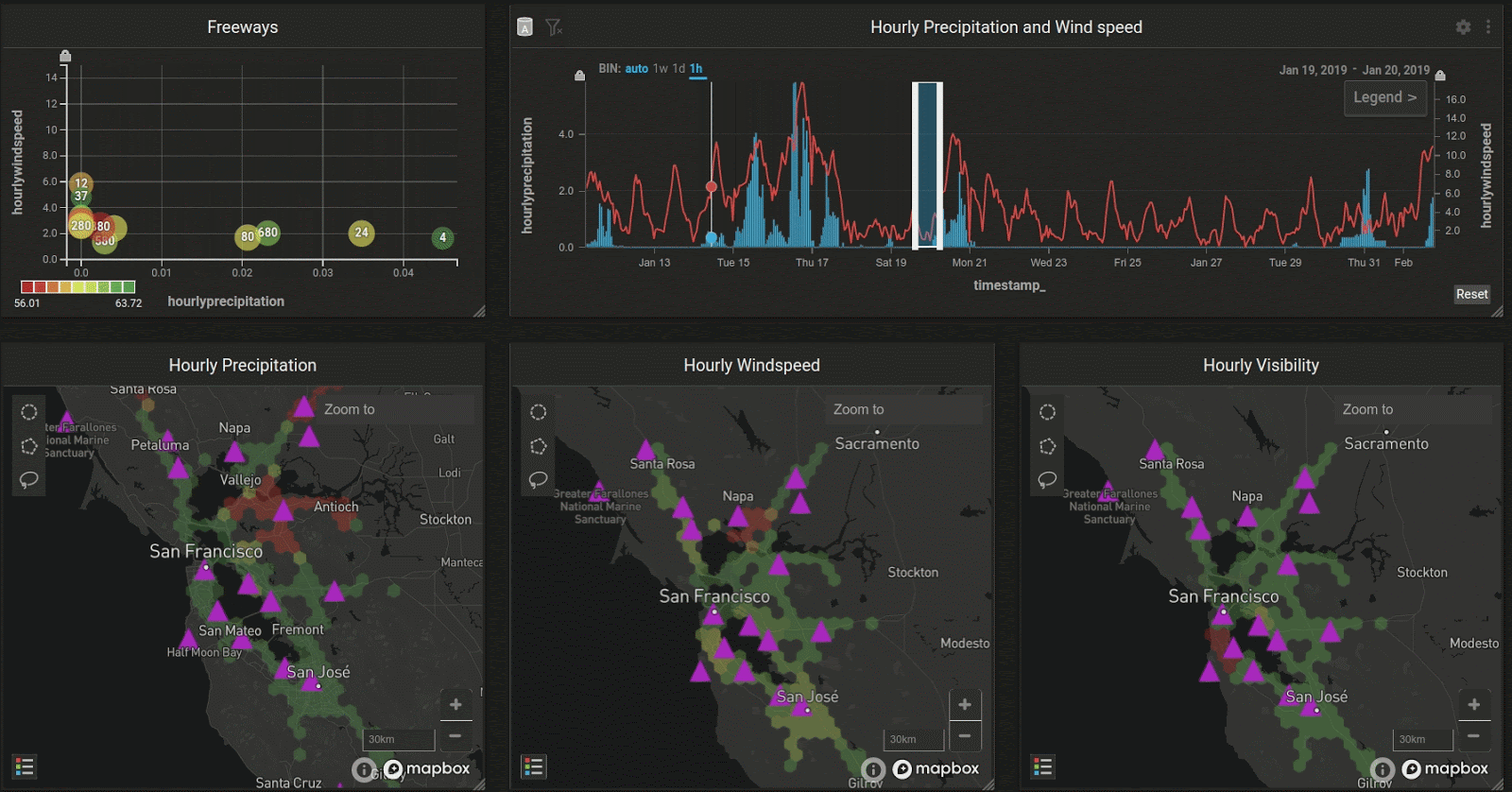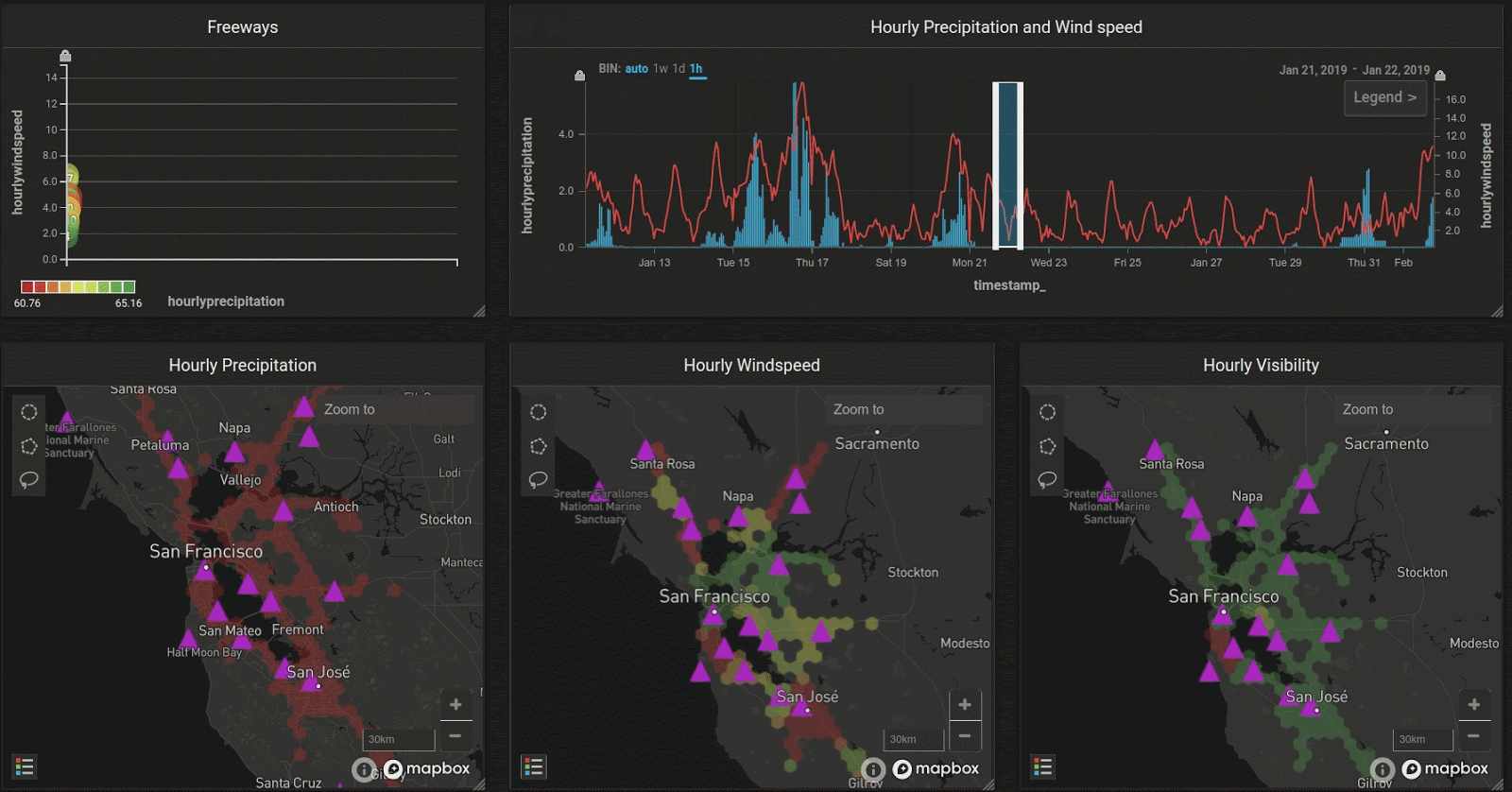
Interestingly, the maps seem to show that although precipitation may be high in a certain region, wind speed could still be low, even though there is a general trend shown in the combo chart (upper right) that wind and precipitation correlate with each other throughout the entire region.
How Does Weather Affect Bay Area Traffic?
So now that we have an understanding of the weather in the region, how does it affect the traffic? At first glance, we can see that rainfall could slow down traffic even though it’s not very apparent. January 15th is significantly slower than the rest of the period and also one of the rainiest days. But the high amount of rain on the 6th didn’t have much impact on the driving.

For a better understanding of how weather affects driving during the day, a heat map shows a bit better representation (OmniSci’s light mode makes this chart a bit easier to read):

The heatmaps show that although weather doesn’t really affect speed at night (the green around the edges), adverse weather has an increasingly negative impact on traffic speed during rush hour times. This makes sense, when there are more cars on the road and rainfall is heavy, drivers tend to be more cautious. Unfortunately, this could also signify that adverse weather could lead to collisions, which would cause a slowdown. To figure out which way the relationship holds, we can incorporate incident data into the analysis.
Incident Data
Caltrans not only provides traffic data from all over California, but also provides incident data. The incident data can be found in the CalTrans data clearinghouse. Let’s look at January - March 2019.
Provided Features
- Incident ID An integer value that uniquely identifies this incident within PeMS.
- Timestamp Date and time of the incident.
- Description A textual description of the incident.
- Location A textual description of the location.
- Area A textual description of the Area. For example, East Sac.
- Latitude Latitude
- Longitude Longitude
- District District number
- Freeway Number Freeway Number
- Freeway Direction A string indicating the freeway direction.
- State Postmile State Postmile
- Absolute Postmile Absolute Postmile
- Duration Incident duration In minutes
Even though the data is pretty clean and easy to use, we should do some simple data processing to make it even better for visualization. The incident data from CalTrans is loaded into Python pandas and processed; refer to the beginning of this Jupyter Notebook for more details.
Incident Data Exploration
There are 31 different labels for the incidents, mostly categorized as either a traffic hazard or a traffic collision:

Unsurprisingly, the density map (below) shows that most incidents happen in the city areas. Of these high incident areas, most occur in San Jose:

However, in the “top 10 most dangerous locations” category which compares intersections, on/off ramps, and stretches of highway, 4 out of 10 are located in San Francisco and the top 3 are also in San Francisco. Even worse, the top 2 locations are the on/off ramp location between I-80 and Treasure Island. The accidents occurring on the I-80 bridge nearest to this intersection are most likely being attributed to this on/off ramp:


Be careful when driving near Treasure Island!
Plotting incidents over time (top), we can see that there is some cyclic nature to incidents, but this trend is easier to view using a heatmap (bottom):


Now we can see that there are definitely some hot spots for incidents. Notably rush hour and especially on Wednesday, that’s when most incidents seem to be happening. Strangely, Monday has less incidents than all the other work-days of the week. Maybe commuters are well rested and more attentive on Monday!
Counting the number of incidents is one lens into the data, but what we really care about is the severity of incidents. To create a numeric representation of incident severity, I mapped each incident type to a severity score: 0 for Traffic hazard (could disrupt traffic but no collision), 1 for minor traffic incidents, or 2 for Collision/Severe incident. Are the work day commute incidents above hazards or full on collisions? And when should we be extra careful when driving?
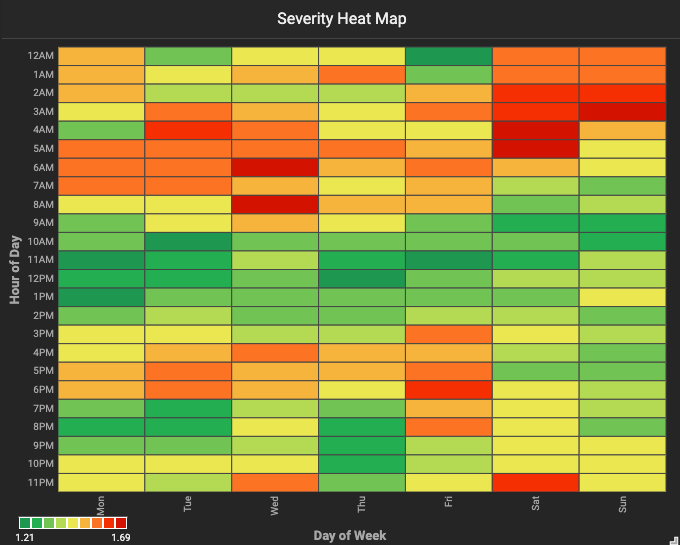
In the severity heat map, we can see that the severity heat map is an almost inverse of the incident heat map. The severity of incidents is dramatically higher at night, especially on the weekends. There may be fewer incidents, but they are more dangerous.

When we investigate further which types of incidents are occurring at the late hours on weekends, it’s a bit frightening. Traffic collisions are more than double the amount of traffic hazards (there are slightly more traffic hazards in the dataset than traffic collisions) and the next reported incidents are hit and runs and wrong way drivers.
Incidents and Weather
Since we also have weather data, we can easily overlay weather and incidents. Could there be a link between inclement weather and number of incidents? What about the severity of incidents and weather?
When looking at the period from January to March, we see some correlation between precipitation and incidents, especially at the peaks. There's also an apparent correlation between severity and precipitation:


Predicting Incidents As a Function of Weather?
In the first two posts in this series, I’ve demonstrated that OmniSci can not only interactively visualize a single billion-row dataset, but that you can also enrich your analyses with other granular data to deeply analyze a complex relationship like traffic. In the final post in this series, I will demonstrate a few data science approaches and tools from the PyData ecosystem to understand the relationship between incidents and weather.
Questions or comments? Stop by the OmniSci Community Forum to let us know what you think!



